






标题:Spark实时计算滑动窗口:高效处理动态数据流的利器
引言
在当今大数据时代,实时数据处理已经成为企业竞争的关键。随着数据量的爆炸性增长,如何高效地处理动态数据流成为了一个亟待解决的问题。Apache Spark作为一款强大的分布式计算框架,提供了实时计算滑动窗口的功能,能够帮助企业实时分析数据,做出快速决策。本文将深入探讨Spark实时计算滑动窗口的原理、应用场景以及实现方法。
什么是滑动窗口
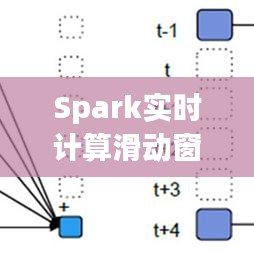
滑动窗口是一种数据处理技术,它将数据流划分为一系列连续的时间窗口,每个窗口包含一定数量的数据点。通过滑动窗口,我们可以对数据流进行实时分析,从而获取实时的业务洞察。
Spark实时计算滑动窗口的原理
Spark实时计算滑动窗口主要基于Spark Streaming和Spark SQL两个组件。Spark Streaming负责实时数据流的接收、处理和输出,而Spark SQL则用于对数据进行查询和分析。
-
Spark Streaming:Spark Streaming可以将实时数据流划分为微批处理(micro-batches),每个微批处理包含一定数量的数据点。通过使用滑动窗口,Spark Streaming可以对这些微批处理进行实时处理。
-
Spark SQL:Spark SQL提供了丰富的查询语言(SQL),可以对Spark Streaming处理后的数据进行查询和分析。通过使用窗口函数,Spark SQL可以轻松实现滑动窗口的实时计算。
Spark实时计算滑动窗口的应用场景
-
实时监控:企业可以通过Spark实时计算滑动窗口,对关键业务指标进行实时监控,如网站流量、用户行为等。
-
实时推荐:在电子商务领域,Spark实时计算滑动窗口可以用于实时推荐系统,根据用户的行为和历史数据,为用户推荐个性化的商品。
-
实时欺诈检测:金融机构可以利用Spark实时计算滑动窗口,对交易数据进行实时分析,从而及时发现并阻止欺诈行为。

实现Spark实时计算滑动窗口的方法
以下是一个简单的Spark实时计算滑动窗口的示例代码:
import org.apache.spark.SparkConf;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
public class SparkSlidingWindowExample {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("Spark Sliding Window Example");
JavaStreamingContext ssc = new JavaStreamingContext(conf, Durations.seconds(1));
JavaDStream<String> lines = ssc.socketTextStream("localhost", 9999);
JavaDStream<String> windowedLines = lines.window(Durations.seconds(5), Durations.seconds(2));
windowedLines.print();
ssc.start();
ssc.awaitTermination();
}
}在这个示例中,我们创建了一个Spark Streaming应用程序,它从本地主机的9999端口接收实时数据。然后,我们使用window()方法创建了一个滑动窗口,窗口大小为5秒,滑动步长为2秒。最后,我们打印出窗口内的数据。
总结
Spark实时计算滑动窗口是一种高效处理动态数据流的技术。通过Spark Streaming和Spark SQL的结合,企业可以实现对实时数据的实时分析,从而做出快速决策。随着大数据技术的不断发展,Spark实时计算滑动窗口将在更多领域发挥重要作用。
转载请注明来自中成网站建设,本文标题:《Spark实时计算滑动窗口:高效处理动态数据流的利器》







 蜀ICP备08106559号-1
蜀ICP备08106559号-1