






标题:Spark实时推送:构建高效数据流处理平台
引言
随着大数据时代的到来,实时数据处理需求日益增长。传统的数据处理方式已经无法满足快速变化的数据流需求。Apache Spark作为一种强大的分布式计算框架,以其高效的数据处理能力和灵活的编程模型,成为了构建实时推送系统的理想选择。本文将探讨如何利用Spark实现实时推送,并分析其优势和应用场景。
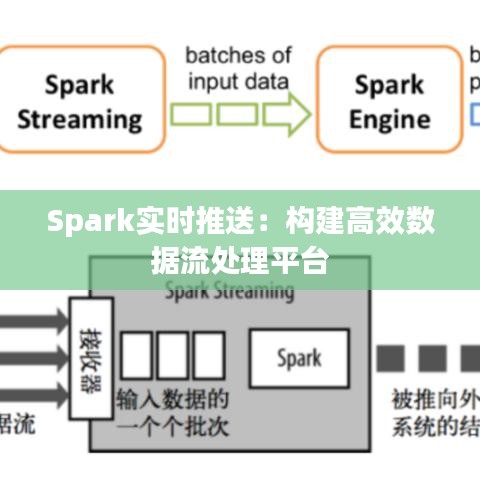
Spark简介
Apache Spark是一个开源的分布式计算系统,它提供了快速的通用数据处理能力。Spark支持多种编程语言,包括Scala、Java、Python和R。其核心特性包括:
- 弹性分布式数据集(RDD):Spark的核心抽象,用于在分布式环境中存储和处理数据。
- Spark SQL:提供了一种用于处理结构化数据的查询语言,支持SQL和DataFrame API。
- 流处理:支持实时数据流处理,可以与Kafka等消息队列集成。
- 机器学习库:提供了一系列机器学习算法,如分类、回归、聚类等。
Spark实时推送架构
Spark实时推送系统通常包括以下几个关键组件:
- 数据源:可以是数据库、文件系统或消息队列等。
- 数据采集器:负责从数据源中读取数据,并将其转换为Spark可处理的格式。
- Spark集群:负责执行数据处理任务,包括数据转换、计算和推送。
- 推送服务:将处理后的数据推送到目标系统,如数据库、缓存或前端应用。
以下是一个简单的Spark实时推送架构示例:
Spark实时推送架构图Spark实时推送实现
要实现Spark实时推送,可以按照以下步骤进行:
- 搭建Spark集群:首先需要搭建一个Spark集群,包括一个Master节点和多个Worker节点。
- 数据采集:使用Spark Streaming或Flume等工具,从数据源中采集数据。
- 数据处理:编写Spark应用程序,对采集到的数据进行转换、计算和过滤。
- 数据推送:将处理后的数据推送到目标系统,如数据库或缓存。
以下是一个简单的Spark Streaming程序示例,用于实时处理Kafka中的数据,并将其推送到数据库:
import org.apache.spark.SparkConf;
import org.apache.spark.streaming.Durations;
import org.apache.spark.streaming.api.java.JavaDStream;
import org.apache.spark.streaming.api.java.JavaStreamingContext;
import org.apache.kafka.common.serialization.StringDeserializer;
import org.apache.spark.streaming.kafka010.ConsumerStrategies;
import org.apache.spark.streaming.kafka010.KafkaUtils;
import org.apache.spark.streaming.kafka010.LocationStrategies;
public class RealtimePushExample {
public static void main(String[] args) {
SparkConf conf = new SparkConf().setAppName("RealtimePushExample");
JavaStreamingContext jssc = new JavaStreamingContext(conf, Durations.seconds(1));
String kafkaBootstrapServers = "localhost:9092";
String inputTopic = "inputTopic";
String outputTopic = "outputTopic";
String groupId = "groupId";
Map<String, Object> kafkaParams = new HashMap<>();
kafkaParams.put("bootstrap.servers", kafkaBootstrapServers);
kafkaParams.put("key.deserializer", StringDeserializer.class);
kafkaParams.put("value.deserializer", StringDeserializer.class);
kafkaParams.put("group.id", groupId);
kafkaParams.put("auto.offset.reset", "latest");
JavaDStream<String> stream = KafkaUtils.createDirectStream(
jssc,
LocationStrategies.PreferConsistent,
ConsumerStrategies.Subscribe<String, String>(Arrays.asList(inputTopic), kafkaParams)
);
stream.mapToPair(record -> new Tuple2<>(record.value(), 1))
.reduceByKey((v1, v2) -> v1 + v2)
.foreachRDD(rdd -> {
rdd.foreachPartition(partitionOfRecords -> {
Connection connection = DriverManager.getConnection("jdbc:mysql://localhost:3306/database", "username", "password");
try {
PreparedStatement statement = connection.prepareStatement("INSERT INTO table (value, count) VALUES (?, ?)");
for (Iterator<Tuple2<String, Integer>> it = partitionOfRecords.iterator(); it.hasNext(); ) {
Tuple2<String, Integer> record = it.next();
statement.setString(1, record._1());
statement.setInt(2, record._2());
statement.executeUpdate();
}转载请注明来自中成网站建设,本文标题:《Spark实时推送:构建高效数据流处理平台》







 蜀ICP备08106559号-1
蜀ICP备08106559号-1